Real-World Architecture Diagram for MongoDB with Sharding & Replication
Learn how real-world companies design scalable MongoDB systems using sharding for high performance and replication for data safety. This guide breaks down each component—mongos, config servers, and shard clusters—with a clear architecture diagram. #MongoDB #Sharding #DevOps
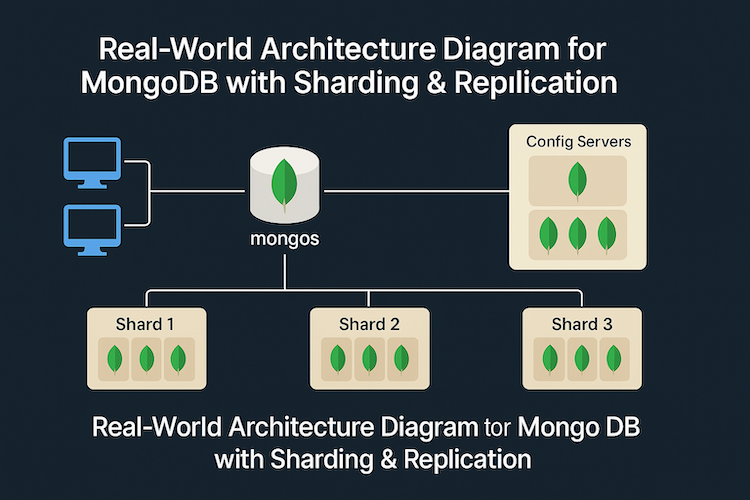
Let’s break down a typical production-grade MongoDB setup:
High-Level Architecture Diagram (Text-Based)
┌──────────────┐ ┌──────────────┐
│ Client │ │ App Server │
│ (Angular App │ │ (Node.js) │
└──────┬───────┘ └──────┬───────┘
│ │
│ HTTP API Requests │
└──────────────▶───────────────┘
│
│ REST API Layer (Express.js)
│ + MongoDB Driver / Mongoose
▼
┌─────────────────────┐
│ Mongos Router │ ◀─── Entry Point
└─────────────────────┘
│
┌──────────────────────────────────────────────────────────┐
│ MongoDB Sharded Cluster │
│ │
│ ┌───────────┐ ┌───────────┐ ┌───────────┐ │
│ │ Shard 1 │ │ Shard 2 │ │ Shard 3 │ │
│ │ Primary + │ │ Primary + │ │ Primary + │ │
│ │ Replicas │ │ Replicas │ │ Replicas │ │
│ └───────────┘ └───────────┘ └───────────┘ │
│ │
│ ┌────────────── Config Servers ──────────────┐ │
│ │ Store Cluster Metadata, Shard Map, etc. │ │
│ └────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────┘
Key Components Explained:
| Component | Purpose |
|---|---|
| Mongos Router | Entry point for app servers, routes queries to right shard |
| Shards | Data partitioned by shard key, each with replicas |
| Replica Sets | Ensure high availability & redundancy within each shard |
| Config Servers | Store cluster state and routing info |
Typical Tech Stack:
- Frontend: Angular (Client UI)
- Backend: Node.js (REST API with Express + Mongoose)
- Database: MongoDB Sharded Cluster (for horizontal scaling + high availability)
- Caching Layer (Optional): Redis for hot data
Sample Production-Ready Aggregation Pipeline (Order Reports)
Here’s a real-world MongoDB aggregation pipeline that summarizes order revenue per product category for reporting dashboards.
db.orders.aggregate([
{
$match: {
orderStatus: "Completed",
orderDate: { $gte: ISODate("2024-01-01") }
}
},
{
$lookup: {
from: "products",
localField: "productIds",
foreignField: "_id",
as: "products"
}
},
{
$unwind: "$products"
},
{
$group: {
_id: "$products.category",
totalRevenue: { $sum: "$products.price" },
totalOrders: { $sum: 1 }
}
},
{
$sort: { totalRevenue: -1 }
},
{
$project: {
category: "$_id",
totalRevenue: 1,
totalOrders: 1,
_id: 0
}
}
]);
Pipeline Explained:
| Stage | Purpose |
|---|---|
$match | Filter only completed orders from Jan 2024 onward |
$lookup | Join products to get category & price |
$unwind | Deconstruct product arrays for aggregation |
$group | Group by category, summing revenue and order count |
$sort | Sort categories by total revenue |
$project | Reshape result for frontend reporting |
Why This Is "Production-Ready" ?
- Filter early with
$matchfor index usage. - Aggregates only necessary fields.
- Reduces output data size for faster API delivery.
- Uses
$lookup+$unwindcarefully (may need denormalization at higher scale).
🎯 Bonus: MongoDB Shard Key Selection Example (E-Commerce)
Good Shard Key:
customerId + regionCode
Why?
- High cardinality: Many unique customers.
- Regional affinity (geo-based apps) → faster local access.
Avoid Bad Shard Keys Like:
- Gender (low uniqueness, poor distribution).
- Boolean flags (true/false causes hotspots).
- Timestamp-only (can cause write hotspots during traffic spikes).
Takeaway for Interviews (And Real-World Projects):
- Your schema design must match your access patterns and future scaling plans.
- Aggregation pipelines should offload heavy computations from the backend API.
- Sharding should only be enabled after understanding long-term traffic patterns.
- Replication must always be tested under failover conditions, not just "enabled."
🚀 Final Thought:
MongoDB, when used correctly, isn't just a document store—it’s a scalable data platform capable of powering enterprise-grade systems. The real power lies in how you combine schema modeling, aggregation, replication, and sharding to match business demands.
More...
Excellent! Here are high-level interview questions (with strong sample answers) tailored for Senior Developer or Architect-level roles focusing on MongoDB—covering schema design, aggregation, sharding, replication, and system architecture.
These answers will help you demonstrate both technical depth and system-level thinking during interviews.
1. How do you approach schema design in MongoDB for a complex application?
Sample Answer (Senior Level):
When designing a schema in MongoDB, my primary focus is query patterns and data lifecycle rather than just data structure. I start by identifying:
- Read/Write frequency per collection
- Relationships between data
- Access patterns (which fields are queried, sorted, and filtered)
I follow the Embed vs. Reference principle:
- I embed documents where data is read together frequently (like user profiles with settings).
- I reference where data is large or reused across multiple collections (e.g., products in orders).
I also ensure:
- Minimal document growth to avoid reallocation overhead.
- Indexing strategies that align with queries.
- Validation rules using Mongoose or MongoDB’s JSON Schema.
- I plan for future scaling, including the possibility of sharding, by choosing shard keys that naturally align with query patterns.
2. Describe a situation where you optimized a complex MongoDB aggregation pipeline.
Sample Answer (Senior Level):
In a recent project, we had a reporting dashboard that aggregated sales data across multiple dimensions—time, region, product category.
Initially, the pipeline used multiple $lookup and $unwind stages, causing slow performance on large datasets.
I optimized it by:
- Filtering early: Moving
$matchstages to the start to reduce data size. - Denormalizing key fields like product categories into the orders collection to eliminate expensive
$lookup. - Rewriting the
$groupstages to minimize memory overhead by grouping on indexed fields first, then post-processing in the app layer. - Testing with
$indexStatsandexplain()to monitor index usage.
Post optimization, aggregation time dropped from ~30 seconds to under 2 seconds for millions of records.
3. Explain how you would choose a shard key in a MongoDB sharded cluster.
Sample Answer (Architect Level):
Choosing a shard key is one of the most critical design decisions in a sharded MongoDB cluster. My approach:
- High Cardinality: The shard key must have many unique values to ensure even distribution.
- Monotonicity Check: Avoid monotonically increasing keys like timestamps to prevent hot shards.
- Query Coverage: The shard key should match the most common query filter to minimize scatter-gather queries.
- Write Distribution: Ensure that write traffic is spread across shards to prevent bottlenecks.
- Predictability: The shard key must align with future data growth and usage patterns.
For example, in multi-tenant SaaS systems, I often use { tenantId, region } as a compound shard key for both balanced distribution and query locality.
4. How would you design a MongoDB deployment for high availability and disaster recovery?
Sample Answer (Architect Level):
For high availability and disaster recovery, I rely on Replica Sets:
- Replica Set Setup: Minimum of 3 nodes—1 primary, 2 secondaries (ideally across different data centers or cloud availability zones).
- Read Scaling: Use secondary nodes for read-heavy workloads with appropriate read preferences.
- Automatic Failover: MongoDB automatically elects a new primary during node failures.
- Backup Strategy: Regular backups using
mongodumpor cloud snapshots, with test restores to verify recoverability. - Monitoring: Set up monitoring with MongoDB Atlas, Prometheus, or New Relic for health checks, replication lag, and performance.
- Arbiter (Optional): In case of odd-numbered voting requirements, I sometimes use an arbiter node—but only if there’s no risk of it being a single point of failure.
I also run failover simulations before production launches to ensure systems automatically recover.
5. How would you scale a system handling billions of transactions per day on MongoDB?
Sample Answer (Architect Level):
To scale MongoDB for extreme workloads:
- Sharded Cluster: Use sharding with a carefully selected shard key to distribute writes/reads evenly.
- Replica Sets within Shards: Each shard itself runs as a replica set for fault tolerance.
- Caching Layer: Integrate Redis or in-memory caches for frequently accessed or static data.
- Async Processing: Offload heavy batch operations to background workers (Node.js queues, Kafka, etc.).
- Schema Optimization: Aggressively denormalize where needed to reduce joins/aggregations during peak loads.
- Indexing & Query Optimization: Continuously refine indexes and use covered queries wherever possible.
- Monitoring & Auto-Scaling: Use cloud auto-scaling for both MongoDB and app layers, with proactive monitoring for throughput and IOPS.
In addition, I would implement Rate Limiting and Traffic Shaping at the API layer to gracefully handle unexpected spikes.
6. Explain the difference between replication and sharding in MongoDB (Senior Level Answer).
Sample Answer:
Replication and sharding serve different but complementary purposes in MongoDB.
| Feature | Replication | Sharding |
|---|---|---|
| Purpose | High availability & data redundancy | Horizontal scaling across multiple nodes |
| Structure | Replica Set (Primary + Secondaries) | Sharded Cluster (Shards + Config Servers) |
| Usage | Disaster recovery, read scaling | Scaling datasets that exceed server limits |
| Failover | Automatic election of new primary | Data is already partitioned across shards |
| Data Copy | Same data on all nodes | Each shard holds part of the data |
In most large-scale systems, I combine both—each shard is a replica set for fault-tolerance + scaling.
7. Describe a real-world system you designed using MongoDB.
Sample Answer (Architect Level):
In one of my previous roles, I led the design of a real-time logistics tracking platform:
- Data involved millions of package scans per day, geolocation updates, and shipment events.
- We chose MongoDB for its flexibility and ease of scaling.
- I designed the schema to embed scan events within shipments for fast tracking.
- For reporting dashboards, I used aggregation pipelines with
$match+$groupstages and caching for results. - To scale writes, we implemented sharding on
{ regionCode, shipmentId }. - Each shard had a replica set across multiple cloud zones for high availability.
- We integrated Redis as a side-cache for hot shipment queries.
- All critical queries were indexed and monitored with Atlas, and we regularly ran capacity planning drills.
This system successfully scaled to handle 100 million+ shipment events monthly with low latency.
Bonus Tips for Senior/Architect Interview:
- When asked about MongoDB, always talk beyond the database—include API caching, queue offloading, and observability.
- Mention trade-offs honestly (e.g., "Sharding adds operational complexity").
- Speak in terms of patterns and principles, not just tools.
- Show your system design thinking: schema → queries → scaling → failover → monitoring.